在过去的大半年里,以Stable Diffusion为代表的AI绘画是世界上最为火热的AI方向之一。或许大家会有疑问,Stable Diffusion里的这个"Diffusion"是什么意思?其实,扩散模型(Diffusion Model)正是Stable Diffusion中负责生成图像的模型。想要理解Stable Diffusion的原理,就一定绕不过扩散模型的学习。

在这篇文章里,我会由浅入深地对最基础的去噪扩散概率模型(Denoising Diffusion Probabilistic Models, DDPM)进行讲解。我会先介绍扩散模型生成图像的基本原理,再用简单的数学语言对扩散模型建模,最后给出扩散模型的一份PyTorch实现。本文不会去堆砌过于复杂的数学公式,哪怕你没有相关的数学背景,也能够轻松理解扩散模型的原理。
扩散模型与图像生成
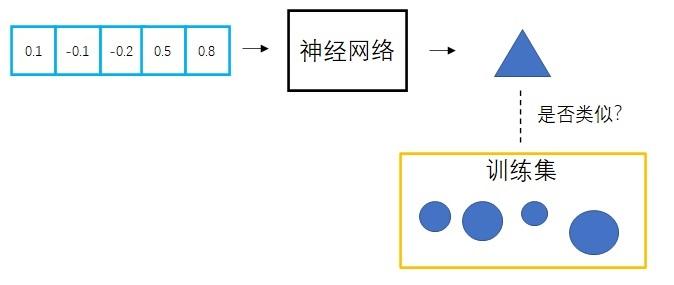
在认识扩散模型之前,我们先退一步,看看一般的神经网络模型是怎么生成图像的。显然,为了生成丰富的图像,一个图像生成程序要根据随机数来生成图像。通常,这种随机数是一个满足标准正态分布的随机向量。这样,每次要生成新图像时,只需要从标准正态分布里随机生成一个向量并输入给程序就行了。
而在AI绘画程序中,负责生成图像的是一个神经网络模型。神经网络需要从数据中学习。对于图像生成任务,神经网络的训练数据一般是一些同类型的图片。比如一个绘制人脸的神经网络会用人脸照片来训练。也就是说,神经网络会学习如何把一个向量映射成一张图片,并确保这个图片和训练集的图片是一类图片。
可是,相比其他AI任务,图像生成任务对神经网络来说更加困难一点——图像生成任务缺乏有效的指导。在其他AI任务中,训练集本身会给出一个「标准答案」,指导AI的输出向标准答案靠拢。比如对于图像分类任务,训练集会给出每一幅图像的类别;对于人脸验证任务,训练集会给出两张人脸照片是不是同一个人;对于目标检测任务,训练集会给出目标的具体位置。然而,图像生成任务是没有标准答案的。图像生成数据集里只有一些同类型图片,却没有指导AI如何画得更好的信息。
为了解决这一问题,人们专门设计了一些用于生成图像的神经网络架构。这些架构中比较出名的有生成对抗模型(GAN)和变分自编码器(VAE)。
GAN的想法是,既然不知道一幅图片好不好,就干脆再训练一个神经网络,用于辨别某图片是不是和训练集里的图片长得一样。生成图像的神经网络叫做生成器,鉴定图像的神经网络叫做判别器。两个网络互相对抗,共同进步。

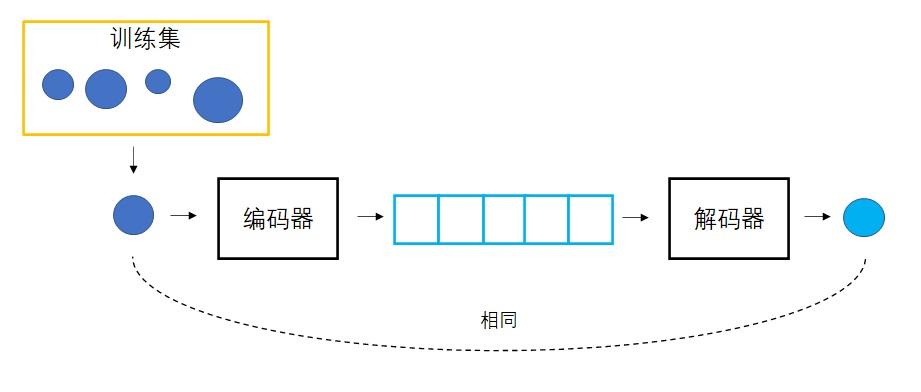
VAE则使用了逆向思维:用向量生成图像很困难,那就同时学习怎么用图像生成向量。这样,把某图像变成向量,再用该向量生成图像,就应该得到一幅和原图像一模一样的图像。每一个向量的绘画结果有了一个标准答案,可以用一般的优化方法来指导网络的训练了。VAE中,把图像变成向量的网络叫做编码器,把向量转换回图像的网络叫做解码器。其中,解码器就是负责生成图像的模型。
一直以来,GAN的生成效果较好,但训练起来比VAE麻烦很多。有没有和GAN一样强大,训练起来又方便的生成网络架构呢?扩散模型正是满足这些要求的生成网络架构。
扩散模型是一种特殊的VAE,其灵感来自于热力学:一个分布可以通过不断地添加噪声变成另一个分布。放到图像生成任务里,就是来自训练集的图像可以通过不断添加噪声变成符合标准正态分布的图像。从这个角度出发,我们可以对VAE做以下修改:1)不再训练一个可学习的编码器,而是把编码过程固定成不断添加噪声的过程;2)不再把图像压缩成更短的向量,而是自始至终都对一个等大的图像做操作。解码器依然是一个可学习的神经网络,它的目的也同样是实现编码的逆操作。不过,既然现在编码过程变成了加噪,那么解码器就应该负责去噪。而对于神经网络来说,去噪任务学习起来会更加有效。因此,扩散模型既不会涉及GAN中复杂的对抗训练,又比VAE更强大一点。
具体来说,扩散模型由正向过程和反向过程这两部分组成,对应VAE中的编码和解码。在正向过程中,输入�0x0会不断混入高斯噪声。经过�T次加噪声操作后,图像��xT会变成一幅符合标准正态分布的纯噪声图像。而在反向过程中,我们希望训练出一个神经网络,该网络能够学会�T个去噪声操作,把��xT还原回�0x0。网络的学习目标是让�T个去噪声操作正好能抵消掉对应的加噪声操作。训练完毕后,只需要从标准正态分布里随机采样出一个噪声,再利用反向过程里的神经网络把该噪声恢复成一幅图像,就能够生成一幅图片了。
高斯噪声,就是一幅各处颜色值都满足高斯分布(正态分布)的噪声图像。
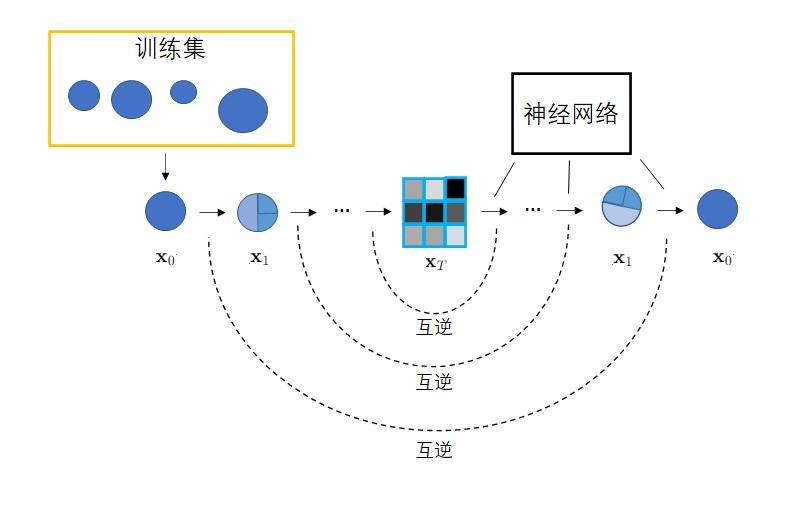
总结一下,图像生成网络会学习如何把一个向量映射成一幅图像。设计网络架构时,最重要的是设计学习目标,让网络生成的图像和给定数据集里的图像相似。VAE的做法是使用两个网络,一个学习把图像编码成向量,另一个学习把向量解码回图像,它们的目标是让复原图像和原图像尽可能相似。学习完毕后,解码器就是图像生成网络。扩散模型是一种更具体的VAE。它把编码过程固定为加噪声,并让解码器学习怎么样消除之前添加的每一步噪声。
扩散模型的具体算法
上一节中,我们只是大概了解扩散模型的整体思想。这一节,我们来引入一些数学表示,来看一看扩散模型的训练算法和采样算法具体是什么。为了便于理解,这一节会出现一些不是那么严谨的数学描述。更加详细的一些数学推导会放到下一节里介绍。
前向过程
在前向过程中,来自训练集的图像�0x0会被添加�T次噪声,使得��xT为符合标准正态分布。准确来说,「加噪声」并不是给上一时刻的图像加上噪声值,而是从一个均值与上一时刻图像相关的正态分布里采样出一幅新图像。如下面的公式所示,��−1xt−1是上一时刻的图像,��xt是这一时刻生成的图像,该图像是从一个均值与��−1xt−1有关的正态分布里采样出来的。
��∼�(��(��−1),��2�)xt∼N(μt(xt−1),σt2I)
多数文章会说前向过程是一个 马尔可夫过程。其实,马尔可夫过程的意思就是当前时刻的状态只由上一时刻的状态决定,而不由更早的状态决定。上面的公式表明,计算��xt,只需要用到��−1xt−1,而不需要用到��−2,��−3...xt−2,xt−3...,这符合马尔可夫过程的定义。
绝大多数扩散模型会把这个正态分布设置成这个形式:
��∼�(1−����−1,���)xt∼N(1−βtxt−1,βtI)
这个正态分布公式乍看起来很奇怪:1−��1−βt是哪里冒出来的?为什么会有这种奇怪的系数?别急,我们先来看另一个问题:假如给定�0x0,也就是从训练集里采样出一幅图片,该怎么计算任意一个时刻�t的噪声图像��xt呢?
我们不妨按照公式,从��xt开始倒推。��xt其实可以通过一个标准正态分布的样本��−1ϵt−1算出来:
��∼�(1−����−1,���)⇒��=1−����−1+����−1;��−1∼�(0,�)xt∼N(1−βtxt−1,βtI)⇒xt=1−βtxt−1+βtϵt−1;ϵt−1∼N(0,I)
再往前推几步:
��=1−����−1+����−1=1−��(1−��−1��−2+��−1��−2)+����−1=(1−��)(1−��−1)��−2+(1−��)��−1��−2+����−1xt=1−βtxt−1+βtϵt−1=1−βt(1−βt−1xt−2+βt−1ϵt−2)+βtϵt−1=(1−βt)(1−βt−1)xt−2+(1−βt)βt−1ϵt−2+βtϵt−1
由正态分布的性质可知,均值相同的正态分布「加」在一起后,方差也会加到一起。也就是�(0,�12�)N(0,σ12I)与�(0,�22�)N(0,σ22I)合起来会得到�(0,(�12+�22)�)N(0,(σ12+σ22)I)。根据这一性质,上面的公式可以化简为:
(1−��)(1−��−1)��−2+(1−��)��−1��−2+����−1=(1−��)(1−��−1)��−2+(1−��)��−1+���=(1−��)(1−��−1)��−2+1−(1−��)(1−��−1)�==(1−βt)(1−βt−1)xt−2+(1−βt)βt−1ϵt−2+βtϵt−1(1−βt)(1−βt−1)xt−2+(1−βt)βt−1+βtϵ(1−βt)(1−βt−1)xt−2+1−(1−βt)(1−βt−1)ϵ
再往前推一步的话,结果是:
(1−��)(1−��−1)(1−��−2)��−3+1−(1−��)(1−��−1)(1−��−2)�(1−βt)(1−βt−1)(1−βt−2)xt−3+1−(1−βt)(1−βt−1)(1−βt−2)ϵ
我们已经能够猜出规律来了,可以一直把公式推到�0x0。令��=1−��,�ˉ�=∏�=1���αt=1−βt,αˉt=∏i=1tαi,则:
��=�ˉ��0+1−�ˉ��xt=αˉtx0+1−αˉtϵ
有了这个公式,我们就可以讨论加噪声公式为什么是��∼�(1−����−1,���)xt∼N(1−βtxt−1,βtI)了。这个公式里的��βt是一个小于1的常数。在DDPM论文中,��βt从�1=10−4β1=10−4到��=0.02βT=0.02线性增长。这样,��βt变大,��αt也越小,�ˉ�αˉt趋于0的速度越来越快。最后,�ˉ�αˉT几乎为0,代入��=�ˉ��0+1−�ˉ��xT=αˉTx0+1−αˉTϵ, ��xT就满足标准正态分布了,符合我们对扩散模型的要求。上述推断可以简单描述为:加噪声公式能够从慢到快地改变原图像,让图像最终均值为0,方差为�I。
反向过程
在正向过程中,我们人为设置了�T步加噪声过程。而在反向过程中,我们希望能够倒过来取消每一步加噪声操作,让一幅纯噪声图像变回数据集里的图像。这样,利用这个去噪声过程,我们就可以把任意一个从标准正态分布里采样出来的噪声图像变成一幅和训练数据长得差不多的图像,从而起到图像生成的目的。
现在问题来了:去噪声操作的数学形式是怎么样的?怎么让神经网络来学习它呢?数学原理表明,当��βt足够小时,每一步加噪声的逆操作也满足正态分布。
��−1∼�(�~�,�~��)xt−1∼N(μ~t,β~tI)
因此,为了描述所有去噪声操作,神经网络应该根据当前的时刻�t、当前的图像��xt,拟合当前时刻的加噪声逆操作的正态分布,也就是拟合当前的均值�~�μ~t和方差�~�β~t。
不要被上文的「去噪声」、「加噪声逆操作」绕晕了哦。由于加噪声是固定的,加噪声的逆操作也是固定的。理想情况下,我们希望去噪操作就等于加噪声逆操作。然而,加噪声的逆操作不太可能从理论上求得,我们只能用一个神经网络去拟合它。去噪声操作和加噪声逆操作的关系,就是神经网络的预测值和真值的关系。
现在问题来了:加噪声逆操作的均值和方差是什么?
直接计算所有数据的加噪声逆操作的分布是不太现实的。但是,如果给定了某个训练集输入�0x0,多了一个限定条件后,该分布是可以用贝叶斯公式计算的(其中�q表示概率分布):
�(��−1∣��,�0)=�(��∣��−1,�0)�(��−1∣�0)�(��∣�0)q(xt−1∣xt,x0)=q(xt∣xt−1,x0)q(xt∣x0)q(xt−1∣x0)
等式左边的�(��−1∣��,�0)=�(��−1;�~�,�~��)q(xt−1∣xt,x0)=N(xt−1;μ~t,β~tI)表示加噪声操作的逆操作,它的均值和方差都是待求的。右边的�(��∣��−1,�0)=�(��;1−����−1,���)q(xt∣xt−1,x0)=N(xt;1−βtxt−1,βtI)是加噪声的分布。而由于�0x0已知,�(��−1∣�0)q(xt−1∣x0)和�(��∣�0)q(xt∣x0)两项可以根据前面的公式��=�ˉ��0+1−�ˉ���xt=αˉtx0+1−αˉtϵt得来:
�(��∣�0)=�(��;�ˉ��0,(1−�ˉ�)�)�(��−1∣�0)=�(��−1;�ˉ�−1�0,(1−�ˉ�−1)�)q(xt∣x0)q(xt−1∣x0)=N(xt;αˉtx0,(1−αˉt)I)=N(xt−1;αˉt−1x0,(1−αˉt−1)I)
这样,等式右边的式子全部已知。我们可以把公式套入,算出给定�0x0时的去噪声分布。经计算化简,分布的均值为:
�~�=1��(��−1−��1−�ˉ���)μ~t=αt1(xt−1−αˉt1−αtϵt)
其中,��ϵt是用公式算��xt时从标准正态分布采样出的样本,它来自公式
��=�ˉ��0+1−�ˉ���xt=αˉtx0+1−αˉtϵt
分布的方差为:
�~�=1−�ˉ�−11−�ˉ�⋅��β~t=1−αˉt1−αˉt−1⋅βt
注意,��βt是加噪声的方差,是一个常量。那么,加噪声逆操作的方差�~�β~t也是一个常量,不与输入�0x0相关。这下就省事了,训练去噪网络时,神经网络只用拟合�T个均值就行,不用再拟合方差了。
知道了均值和方差的真值,训练神经网络只差最后的问题了:该怎么设置训练的损失函数?加噪声逆操作和去噪声操作都是正态分布,网络的训练目标应该是让每对正态分布更加接近。那怎么用损失函数描述两个分布尽可能接近呢?最直观的想法,肯定是让两个正态分布的均值尽可能接近,方差尽可能接近。根据上文的分析,方差是不用控制的,只用让均值尽可能接近就可以了。
那怎么用数学公式表达让均值更接近呢?再观察一下目标均值的公式:
�~�=1��(��−1−��1−�ˉ���)μ~t=αt1(xt−1−αˉt1−αtϵt)
神经网络拟合均值时,��xt是已知的(别忘了,图像是一步一步倒着去噪的)。式子里唯一不确定的只有��ϵt。既然如此,神经网络干脆也别预测均值了,直接预测一个噪声��(��,�)ϵθ(xt,t)(其中�θ为可学习参数),让它和生成��xt的噪声��ϵt的均方误差最小就行了。对于一轮训练,最终的误差函数可以写成
�=∣∣��−��(��,�)∣∣2L=∣∣ϵt−ϵθ(xt,t)∣∣2
这样,我们就认识了反向过程的所有内容。总结一下,反向过程中,神经网络应该让�T个去噪声操作拟合对应的�T个加噪声逆操作。每步加噪声逆操作符合正态分布,且在给定某个输入时,该正态分布的均值和方差是可以用解析式表达出来的。神经网络的学习目标就是让其输出的分布和理论计算的分布一致。经过数学计算上的一些化简,问题被转换成了拟合生成��xt时用到的随机噪声��ϵt。
训练算法与采样算法
理解了前向过程和反向过程后,训练神经网络的算法和采样图片(生成图片)的算法就呼之欲出了。
以下是DDPM论文中的训练算法:

让我们来逐行理解一下这个算法。第二行是指从训练集里取一个数据�0x0。第三行是指随机从1,...,�1,...,T里取一个时刻用来训练。我们虽然要求神经网络拟合�T个正态分布,但实际训练时,不用一轮预测�T个结果,只需要随机预测�T个时刻中某一个时刻的结果就行。第四行指随机生成一个噪声�ϵ,该噪声是用于执行前向过程生成��=�ˉ��0+1−�ˉ��xt=αˉtx0+1−αˉtϵ的。之后,我们把��xt和�t传给神经网络��(��,�)ϵθ(xt,t),让神经网络预测随机噪声。训练的损失函数是预测噪声和实际噪声之间的均方误差,对此损失函数采用梯度下降即可优化网络。
DDPM并没有规定神经网络的结构。根据任务的难易程度,我们可以自己定义简单或复杂的网络结构。这里只需要把��(��,�)ϵθ(xt,t)当成一个普通的映射即可。
训练好了网络后,我们可以执行反向过程,对任意一幅噪声图像去噪,以实现图像生成。这个算法如下:

第一行的��xt就是从标准正态分布里随机采样的输入噪声。要生成不同的图像,只需要更换这个噪声。后面的过程就是扩散模型的反向过程。令时刻从�T到11,计算这一时刻去噪声操作的均值和方差,并采样出��−1xt−1。均值是用之前提到的公式计算的:
��(��,�)=1��(��−1−��1−�ˉ���(��,�))μθ(xt,t)=αt1(xt−1−αˉt1−αtϵθ(xt,t))
而方差��2σt2的公式有两种选择,两个公式都能产生差不多的结果。实验表明,当�0x0是特定的某个数据时,用上一节推导出来的方差最好。
��2=1−�ˉ�−11−�ˉ�⋅��σt2=1−αˉt1−αˉt−1⋅βt
而当�0∼�(0,�)x0∼N(0,I)时,只需要令方差和加噪声时的方差一样即可。
��2=��σt2=βt
循环执行去噪声操作。最后生成的�0x0就是生成出来的图像。
特别地,最后一步去噪声是不用加方差项的。为什么呢,观察公式��2=1−�ˉ�−11−�ˉ�⋅��σt2=1−αˉt1−αˉt−1⋅βt。当�=1t=1时,分子会出现�ˉ�−1=�ˉ0αˉt−1=αˉ0这一项。�ˉ�αˉt是一个连乘,理论上�t是从11开始的,在�=0t=0时没有定义。但我们可以特别地令�ˉ0=1αˉ0=1。这样,�=1t=1时方差项的分子1−�ˉ�−11−αˉt−1为00,不用算这一项了。
当然,这一解释从数学上来说是不严谨的。据论文说,这部分的解释可以参见朗之万动力学。
数学推导的补充 (选读)
理解了训练算法和采样算法,我们就算是搞懂了扩散模型,可以去编写代码了。不过,上文的描述省略了一些数学推导的细节。如果对扩散模型更深的原理感兴趣,可以阅读一下本节。
加噪声逆操作均值和方差的推导
上一节,我们根据下面几个式子
�(��−1∣��,�0)=�(��∣��−1,�0)�(��−1∣�0)�(��∣�0)�(��∣�0)=�(��;�ˉ��0,(1−�ˉ�)�)�(��∣��−1,�0)=�(��;1−����−1,���)q(xt−1∣xt,x0)=q(xt∣xt−1,x0)q(xt∣x0)q(xt−1∣x0)q(xt∣x0)=N(xt;αˉtx0,(1−αˉt)I)q(xt∣xt−1,x0)=N(xt;1−βtxt−1,βtI)
一步就给出了�(��−1∣��,�0)=�(��−1;�~�,�~��)q(xt−1∣xt,x0)=N(xt−1;μ~t,β~tI)的均值和方差。
�~�=1��(��−1−��1−�ˉ���)μ~t=αt1(xt−1−αˉt1−αtϵt)
�~�=1−�ˉ�−11−�ˉ�⋅��β~t=1−αˉt1−αˉt−1⋅βt
现在我们来看一下推导均值和方差的思路。
首先,把其他几个式子带入贝叶斯公式的等式右边。
�(��−1∣��,�0)=1��2����(−(��−1−����−1)22��)⋅1(1−�ˉ�−1)2����(−(��−1−�ˉ�−1�0)22(1−�ˉ�−1))⋅(1(1−�ˉ�)2����(−(��−�ˉ��0)22(1−�ˉ�)))−1q(xt−1∣xt,x0)=βt2π1exp(−2βt(xt−1−βtxt−1)2)⋅(1−αˉt−1)2π1exp(−2(1−αˉt−1)(xt−1−αˉt−1x0)2)⋅((1−αˉt)2π1exp(−2(1−αˉt)(xt−αˉtx0)2))−1
由于多个正态分布的乘积还是一个正态分布,我们知道�(��−1∣��,�0)q(xt−1∣xt,x0)也可以用一个正态分布公式�(��−1;�~�,�~��)N(xt−1;μ~t,β~tI)表达,它最后一定能写成这种形式:
�(��−1∣��,�0)=1�~�2����(−(��−1−�~�)22�~�)q(xt−1∣xt,x0)=β~t2π1exp(−2β~t(xt−1−μ~t)2)
问题就变成了怎么把开始那个很长的式子化简,算出�~�μ~t和�~�β~t。
方差�~�β~t可以从指数函数的系数得来,比较好求。系数为
1��2�⋅1(1−�ˉ�−1)2�⋅(1(1−�ˉ�)2�)−1=(1−�ˉ�)��(1−�ˉ�−1)2�=βt2π1⋅(1−αˉt−1)2π1⋅((1−αˉt)2π1)−1βt(1−αˉt−1)2π(1−αˉt)
所以,方差为:
�~�=1−�ˉ�−11−�ˉ�⋅��β~t=1−αˉt1−αˉt−1⋅βt
接下来只要关注指数函数的指数部分。指数部分一定是一个关于的��−1xt−1的二次函数,只要化简成(��−1−�)2(xt−1−C)2的形式,再除以一下−2−2倍方差,就可以得到均值了。
指数部分为:
−12((��−1−����−1)2��+(��−1−�ˉ�−1�0)21−�ˉ�−1−(��−�ˉ��0)21−�ˉ�)−21(βt(xt−1−βtxt−1)2+1−αˉt−1(xt−1−αˉt−1x0)2−1−αˉt(xt−αˉtx0)2)
��−1xt−1只在前两项里有。把和��−1xt−1有关的项计算化简,可以计算出均值:
�~�=��(1−�ˉ�−1)1−�ˉ���+�ˉ�−1��1−�ˉ��0μ~t=1−αˉtαt(1−αˉt−1)xt+1−αˉtαˉt−1βtx0
回想一下,在去噪声中,神经网络的输入是��xt和�t。也就是说,上式中��xt已知,只有�0x0一个未知量。要算均值,还需要算出�0x0。�0x0和��xt之间是有一定联系的。��xt是�0x0在正向过程中第�t步加噪声的结果。而根据正向过程的公式:
��=�ˉ��0+1−�ˉ����0=��−1−�ˉ����ˉ�xtx0=αˉtx0+1−αˉtϵt=αˉtxt−1−αˉtϵt
把这个�0x0带入均值公式,均值最后会化简成我们熟悉的形式。
�~�=1��(��−1−��1−�ˉ���)μ~t=αt1(xt−1−αˉt1−αtϵt)
优化目标
上一节,我们只是简单地说神经网络的优化目标是让加噪声和去噪声的均值接近。而让均值接近,就是让生成��xt的噪声��ϵt更接近。实际上,这个优化目标是经过简化得来的。扩散模型最早的优化目标是有一定的数学意义的。
扩散模型,全称为扩散概率模型(Diffusion Probabilistic Model)。最简单的一类扩散模型,是去噪扩散概率模型(Denoising Diffusion Probabilistic Model),也就是常说的DDPM。DDPM的框架主要是由两篇论文建立起来的。第一篇论文是首次提出扩散模型思想的Deep Unsupervised Learning using Nonequilibrium Thermodynamics。在此基础上,Denoising Diffusion Probabilistic Models对最早的扩散模型做出了一定的简化,让图像生成效果大幅提升,促成了扩散模型的广泛使用。我们上一节看到的公式,全部是简化后的结果。
扩散概率模型的名字之所以有「概率」二字,是因为这个模型是在描述一个系统的概率。准确来说,扩散模型是在描述经反向过程生成出某一项数据的概率。也就是说,扩散模型��(�0)pθ(x0)是一个有着可训练参数�θ的模型,它描述了反向过程生成出数据�0x0的概率。��(�0)pθ(x0)满足��(�0)=∫��(�0:�)��1:�pθ(x0)=∫pθ(x0:T)dx1:T,其中��(�0:�)pθ(x0:T)就是我们熟悉的反向过程,只不过它是以概率计算的形式表达:
��(�0:�)=�(��)∏�−1���(��−1∣��)pθ(x0:T)=p(xT)t−1∏Tpθ(xt−1∣xt)
��(��−1∣��)=�(��−1;��(��,�),Σ�(��,�))pθ(xt−1∣xt)=N(xt−1;μθ(xt,t),Σθ(xt,t))
我们上一节里见到的优化目标,是让去噪声操作��(��−1∣��)pθ(xt−1∣xt)和加噪声操作的逆操作�(��−1∣��,�0)q(xt−1∣xt,x0)尽可能相似。然而,这个对描述并不确切。扩散模型原本的目标,是最大化��(�0)pθ(x0)这个概率,其中�0x0是来自训练集的数据。换个角度说,给定一个训练集的数据�0x0,经过前向过程和反向过程,扩散模型要让复原出�0x0的概率尽可能大。这也是我们在本文开头认识VAE时见到的优化目标。
最大化��(�0)pθ(x0),一般会写成最小化其负对数值,即最小化−��� ��(�0)−log pθ(x0)。使用和VAE类似的变分推理,可以把优化目标转换成优化一个叫做变分下界(variational lower bound, VLB)的量。它最终可以写成:
����=�[���(�(��∣�0)∣∣��(��))+∑�=2����(�(��−1∣��,�0)∣∣��(��−1∣��))−�����(�0∣�1)]LVLB=E[DKL(q(xT∣x0)∣∣pθ(xT))+t=2∑TDKL(q(xt−1∣xt,x0)∣∣pθ(xt−1∣xt))−logpθ(x0∣x1)]
这里的���(�∣∣�)DKL(P∣∣Q)表示分布P和Q之间的KL散度。KL散度是衡量两个分布相似度的指标。如果�,�P,Q都是正态分布,则它们的KL散度可以由一个简单的公式给出。关于KL散度的知识可以参见我之前的文章: 从零理解熵、交叉熵、KL散度。
其中,第一项���(�(��∣�0)∣∣��(��))DKL(q(xT∣x0)∣∣pθ(xT))和可学习参数�θ无关(因为可学习参数只描述了每一步去噪声操作,也就是只描述了��(��−1∣��)pθ(xt−1∣xt)),可以不去管它。那么这个优化目标就由两部分组成:
- 最小化���(�(��−1∣��,�0)∣∣��(��−1∣��))DKL(q(xt−1∣xt,x0)∣∣pθ(xt−1∣xt))表示的是最大化每一个去噪声操作和加噪声逆操作的相似度。
- 最小化−�����(�0∣�1)−logpθ(x0∣x1)就是已知�1x1时,让最后复原原图�0x0概率更高。
我们分别看这两部分是怎么计算的。
对于第一部分,我们先回顾一下正态分布之间的KL散度公式。设一维正态分布�,�P,Q的公式如下:
�(�)=12��1���(−(�−�1)22�12)�(�)=12��2���(−(�−�2)22�22)P(x)=2πσ11exp(−2σ12(x−μ1)2)Q(x)=2πσ21exp(−2σ22(x−μ2)2)
则
���(�∣∣�)=����2�1+�12+(�1−�2)22�22−12DKL(P∣∣Q)=logσ1σ2+2σ22σ12+(μ1−μ2)2−21
而对于���(�(��−1∣��,�0)∣∣��(��−1∣��))DKL(q(xt−1∣xt,x0)∣∣pθ(xt−1∣xt)),根据前文的分析,我们知道,待求方差Σ�(��,�)Σθ(xt,t)可以直接由计算得到。
Σ�(��,�)=�~��=1−�ˉ�−11−�ˉ�⋅���Σθ(xt,t)=β~tI=1−αˉt1−αˉt−1⋅βtI
二者的比值是常量。所以,在计算KL散度时,不用管方差那一项了,只需要管均值那一项。
���(�(��−1∣��,�0)∣∣��(��−1∣��))→12�~�2∣∣��(��,�)−�~�(��,�)∣∣2DKL(q(xt−1∣xt,x0)∣∣pθ(xt−1∣xt))→2β~t21∣∣μθ(xt,t)−μ~t(xt,t)∣∣2
由根据之前的均值公式
�~�(��,�)=1��(��−1−��1−�ˉ���)μ~t(xt,t)=αt1(xt−1−αˉt1−αtϵt)
��(��,�)=1��(��−1−��1−�ˉ���(��,�))μθ(xt,t)=αt1(xt−1−αˉt1−αtϵθ(xt,t))
这一部分的优化目标可以化简成
(1−��)22��(1−�ˉ�)�~�2∣∣��−��(��,�)∣∣22αt(1−αˉt)β~t2(1−αt)2∣∣ϵt−ϵθ(xt,t)∣∣2
DDPM论文指出,如果把前面的系数全部丢掉的话,模型的效果更好。最终,我们就能得到一个非常简单的优化目标:
∣∣��−��(��,�)∣∣2∣∣ϵt−ϵθ(xt,t)∣∣2
这就是我们上一节见到的优化目标。
当然,还没完,别忘了优化目标里还有−�����(�0∣�1)−logpθ(x0∣x1)这一项。它的形式为:
−�����(�0∣�1)=−���12��~12+∣∣�0−��(�1,1)∣∣22�~12−logpθ(x0∣x1)=−log2πβ~121+2β~12∣∣x0−μθ(x1,1)∣∣2
只管后面有�θ的那一项(注意,�1=�ˉ1=1−�1α1=αˉ1=1−β1):
(�0−��(�1,1))22�~12=12�~12∣∣�0−1�1(�1−1−�11−�ˉ1��(�1,1))∣∣2=12�~12∣∣�0−1�1(�ˉ1�0+1−�ˉ1�1−1−�11−�ˉ1��(�1,1))∣∣2=12�~12�1∣∣1−�ˉ1�1−1−�11−�ˉ1��(�1,1)∣∣2=1−�ˉ12�~12�1∣∣�1−��(�1,1)∣∣22β~12(x0−μθ(x1,1))2=2β~121∣∣x0−α11(x1−1−αˉ11−α1ϵθ(x1,1))∣∣2=2β~121∣∣x0−α11(αˉ1x0+1−αˉ1ϵ1−1−αˉ11−α1ϵθ(x1,1))∣∣2=2β~12α11∣∣1−αˉ1ϵ1−1−αˉ11−α1ϵθ(x1,1)∣∣2=2β~12α11−αˉ1∣∣ϵ1−ϵθ(x1,1)∣∣2
这和那些KL散度项�=1t=1时的形式相同,我们可以用相同的方式简化优化目标,只保留∣∣�1−��(�1,1)∣∣2∣∣ϵ1−ϵθ(x1,1)∣∣2。这样,损失函数的形式全都是∣∣��−��(��,�)∣∣2∣∣ϵt−ϵθ(xt,t)∣∣2了。
DDPM论文里写−�����(�0∣�1)−logpθ(x0∣x1)这一项可以直接满足简化后的公式�=1t=1时的情况,而没有去掉系数的过程。我在网上没找到文章解释这一点,只好按自己的理解来推导这个误差项了。不论如何,推导的过程不是那么重要,重要的是最后的简化形式。
总结
图像生成任务就是把随机生成的向量(噪声)映射成和训练图像类似的图像。为此,扩散模型把这个过程看成是对纯噪声图像的去噪过程。通过学习把图像逐步变成纯噪声的逆操作,扩散模型可以把任何一个纯噪声图像变成有意义的图像,也就是完成图像生成。
对于不同程度的读者,应该对本文有不同的认识。
对于只想了解扩散模型大概原理的读者,只需要阅读第一节,并大概了解:
- 图像生成任务的通常做法
- 图像生成任务需要监督
- VAE通过把图像编码再解码来训练一个解码器
- 扩散模型是一类特殊的VAE,它的编码固定为加噪声,解码固定为去噪声
对于想认真学习扩散模型的读者,只需读懂第二节的主要内容:
- 扩散模型的优化目标:让反向过程尽可能成为正向过程的逆操作
- 正向过程的公式
- 反向过程的做法(采样算法)
- 加噪声逆操作的均值和方差在给定�0x0时可以求出来的,加噪声逆操作的均值就是去噪声的学习目标
- 简化后的损失函数与训练算法
对有学有余力对数学感兴趣的读者,可以看一看第三节的内容:
- 加噪声逆操作均值和方差的推导
- 扩散模型最早的优化目标与DDPM论文是如何简化优化目标的
我个人认为,由于扩散模型的优化目标已经被大幅度简化,除非你的研究目标是改进扩散模型本身,否则没必要花过多的时间钻研数学原理。在学习时,建议快点看懂扩散模型的整体思想,搞懂最核心的训练算法和采样算法,跑通代码。之后就可以去看较新的论文了。
在附录中,我给出了一份DDPM的简单实现。欢迎大家参考,并自己动手复现一遍DDPM。
参考资料与学习建议
网上绝大多数的中英文教程都是照搬 https://lilianweng.github.io/posts/2021-07-11-diffusion-models/ 这篇文章的。这篇文章像教科书一样严谨,适合有一定数学基础的人阅读,但不适合给初学者学习。建议在弄懂扩散模型的大概原理后再来阅读这篇文章补充细节。
多数介绍扩散模型的文章对没学过相关数学知识的人来说很不友好,我在阅读此类文章时碰到了大量的问题:为什么前向公式里有个1−�1−β?为什么突然冒出一个快速算��xt的公式?为什么反向过程里来了个贝叶斯公式?优化目标是什么?−��� ��(�0)−log pθ(x0)是什么?为什么优化目标里一大堆项,每一项的意义又是什么?为什么最后莫名其妙算一个�ϵ?为什么采样时�=0t=0就不用加方差项了?好不容易,我才把这些问题慢慢搞懂,并在本文做出了解释。希望我的解答能够帮助到同样有这些困惑的读者。想逐步学习扩散模型,可以先看懂我这篇文章的大概讲解,再去其他文章里学懂一些细节。无论是教,还是学,最重要的都是搞懂整体思路,知道动机,最后再去强调细节。
这里还有篇文章给出了扩散模型中数学公式的详细推导,并补充了变分推理的背景介绍,适合从头学起:https://arxiv.org/abs/2208.11970
想深入学习DDPM,可以看一看最重要的两篇论文:Deep Unsupervised Learning using Nonequilibrium Thermodynamics、Denoising Diffusion Probabilistic Models。当然,后者更重要一些,里面的一些实验结果仍有阅读价值。
我在代码复现时参考了这篇文章。相对于网上的其他开源DDPM实现,这份代码比较简短易懂,更适合学习。不过,这份代码有一点问题。它的神经网络不够强大,采样结果会有一点问题。
附录:代码复现
在这个项目中,我们要用PyTorch实现一个基于U-Net的DDPM,并在MNIST数据集(经典的手写数字数据集)上训练它。模型几分钟就能训练完,我们可以方便地做各种各样的实验。
后续讲解只会给出代码片段,完整的代码请参见 https://github.com/SingleZombie/DL-Demos/tree/master/dldemos/ddpm 。git clone 仓库并安装后,可以直接运行目录里的main.py训练模型并采样。
获取数据集
PyTorch的torchvision提供了获取了MNIST的接口,我们只需要用下面的函数就可以生成MNIST的Dataset实例。参数中,root为数据集的下载路径,download为是否自动下载数据集。令download=True的话,第一次调用该函数时会自动下载数据集,而第二次之后就不用下载了,函数会读取存储在root里的数据。
mnist = torchvision.datasets.MNIST(root='./data/mnist', download=True)
我们可以用下面的代码来下载MNIST并输出该数据集的一些信息:
import torchvision
from torchvision.transforms import ToTensor
def download_dataset():
mnist = torchvision.datasets.MNIST(root='./data/mnist', download=True)
print('length of MNIST', len(mnist))
id = 4
img, label = mnist[id]
print(img)
print(label)
# On computer with monitor
# img.show()
img.save('work_dirs/tmp.jpg')
tensor = ToTensor()(img)
print(tensor.shape)
print(tensor.max())
print(tensor.min())
if __name__ == '__main__':
download_dataset()
执行这段代码,输出大致为:
length of MNIST 60000 <PIL.Image.Image image mode=L size=28x28 at 0x7FB3F09CCE50> 9 torch.Size([1, 28, 28]) tensor(1.) tensor(0.)
第一行输出表明,MNIST数据集里有60000张图片。而从第二行和第三行输出中,我们发现每一项数据由图片和标签组成,图片是大小为28x28的PIL格式的图片,标签表明该图片是哪个数字。我们可以用torchvision里的ToTensor()把PIL图片转成PyTorch张量,进一步查看图片的信息。最后三行输出表明,每一张图片都是单通道图片(灰度图),颜色值的取值范围是0~1。
我们可以查看一下每张图片的样子。如果你是在用带显示器的电脑,可以去掉img.show那一行的注释,直接查看图片;如果你是在用服务器,可以去img.save的路径里查看图片。该图片的应该长这个样子:
我们可以用下面的代码预处理数据并创建DataLoader。由于DDPM会把图像和正态分布关联起来,我们更希望图像颜色值的取值范围是[-1, 1]。为此,我们可以对图像做一个线性变换,减0.5再乘2。
def get_dataloader(batch_size: int):
transform = Compose([ToTensor(), Lambda(lambda x: (x - 0.5) * 2)])
dataset = torchvision.datasets.MNIST(root='./data/mnist',
transform=transform)
return DataLoader(dataset, batch_size=batch_size, shuffle=True)
DDPM 类
在代码中,我们要实现一个DDPM类。它维护了扩散过程中的一些常量(比如�α),并且可以计算正向过程和反向过程的结果。
先来实现一下DDPM类的初始化函数。一开始,我们遵从论文的配置,用torch.linspace(min_beta, max_beta, n_steps)从min_beta到max_beta线性地生成n_steps个时刻的�β。接着,我们根据公式��=1−��,�ˉ�=∏�=1���αt=1−βt,αˉt=∏i=1tαi,计算每个时刻的alpha和alpha_bar。注意,为了方便实现,我们让t的取值从0开始,要比论文里的�t少1。
import torch
class DDPM():
# n_steps 就是论文里的 T
def __init__(self,
device,
n_steps: int,
min_beta: float = 0.0001,
max_beta: float = 0.02):
betas = torch.linspace(min_beta, max_beta, n_steps).to(device)
alphas = 1 - betas
alpha_bars = torch.empty_like(alphas)
product = 1
for i, alpha in enumerate(alphas):
product *= alpha
alpha_bars[i] = product
self.betas = betas
self.n_steps = n_steps
self.alphas = alphas
self.alpha_bars = alpha_bars
部分实现会让 DDPM 继承torch.nn.Module,但我认为这样不好。DDPM本身不是一个神经网络,它只是描述了前向过程和后向过程的一些计算。只有涉及可学习参数的神经网络类才应该继承torch.nn.Module。
准备好了变量后,我们可以来实现DDPM类的其他方法。先实现正向过程方法,该方法会根据公式��=�ˉ��0+1−�ˉ���xt=αˉtx0+1−αˉtϵt计算正向过程中的��xt。
def sample_forward(self, x, t, eps=None):
alpha_bar = self.alpha_bars[t].reshape(-1, 1, 1, 1)
if eps is None:
eps = torch.randn_like(x)
res = eps * torch.sqrt(1 - alpha_bar) + torch.sqrt(alpha_bar) * x
return res
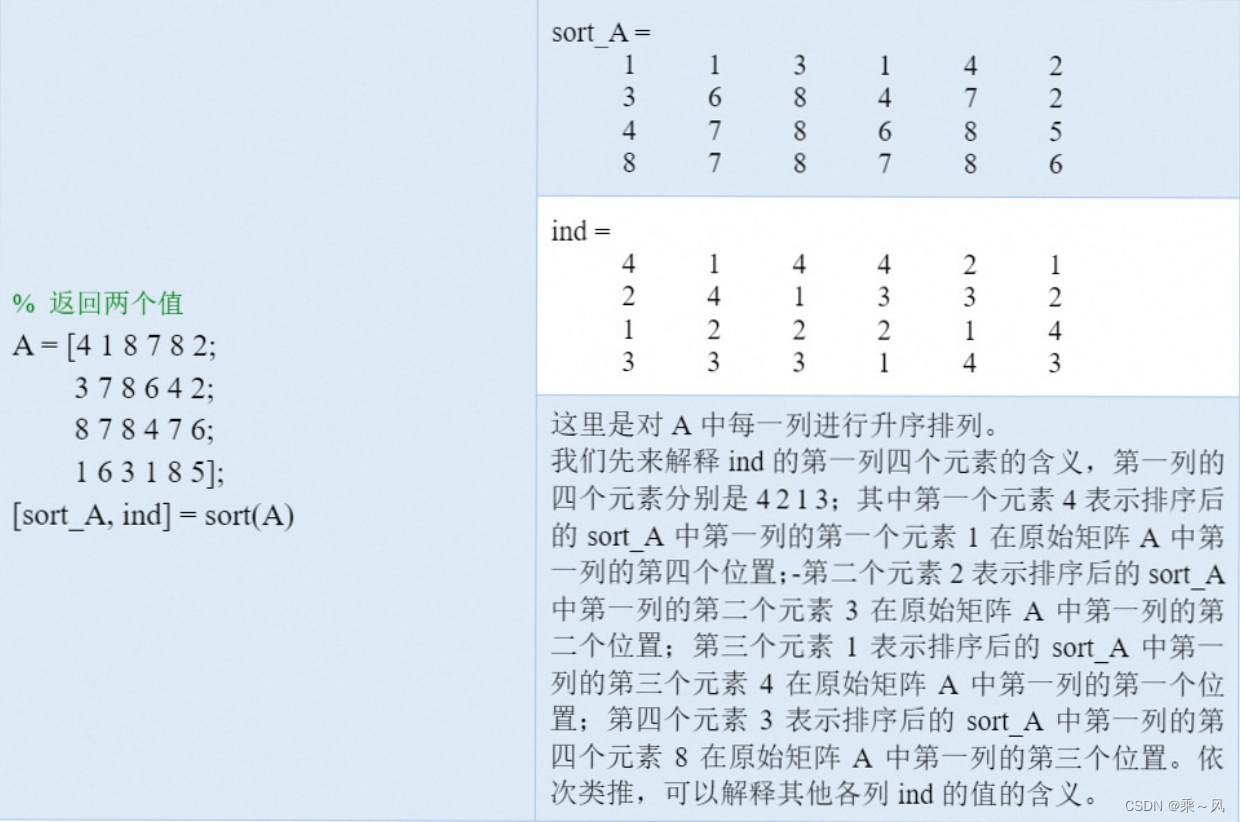
这里要解释一些PyTorch编程上的细节。这份代码中,self.alpha_bars是一个一维Tensor。而在并行训练中,我们一般会令t为一个形状为(batch_size, )的Tensor。PyTorch允许我们直接用self.alpha_bars[t]从self.alpha_bars里取出batch_size个数,就像用一个普通的整型索引来从数组中取出一个数一样。有些实现会用torch.gather从self.alpha_bars里取数,其作用是一样的。
我们可以随机从训练集取图片做测试,看看它们在前向过程中是怎么逐步变成噪声的。

接下来实现反向过程。在反向过程中,DDPM会用神经网络预测每一轮去噪的均值,把��xt复原回�0x0,以完成图像生成。反向过程即对应论文中的采样算法。
其实现如下:
def sample_backward(self, img_shape, net, device, simple_var=True):
x = torch.randn(img_shape).to(device)
net = net.to(device)
for t in range(self.n_steps - 1, -1, -1):
x = self.sample_backward_step(x, t, net, simple_var)
return x
def sample_backward_step(self, x_t, t, net, simple_var=True):
n = x_t.shape[0]
t_tensor = torch.tensor([t] * n,
dtype=torch.long).to(x_t.device).unsqueeze(1)
eps = net(x_t, t_tensor)
if t == 0:
noise = 0
else:
if simple_var:
var = self.betas[t]
else:
var = (1 - self.alpha_bars[t - 1]) / (
1 - self.alpha_bars[t]) * self.betas[t]
noise = torch.randn_like(x_t)
noise *= torch.sqrt(var)
mean = (x_t -
(1 - self.alphas[t]) / torch.sqrt(1 - self.alpha_bars[t]) *
eps) / torch.sqrt(self.alphas[t])
x_t = mean + noise
return x_t
其中,sample_backward是用来给外部调用的方法,而sample_backward_step是执行一步反向过程的方法。
sample_backward会随机生成纯噪声x(对应��xT),再令t从n_steps - 1到0,调用sample_backward_step。
def sample_backward(self, img_shape, net, device, simple_var=True):
x = torch.randn(img_shape).to(device)
net = net.to(device)
for t in range(self.n_steps - 1, -1, -1):
x = self.sample_backward_step(x, t, net, simple_var)
return x
在sample_backward_step中,我们先准备好这一步的神经网络输出eps。为此,我们要把整型的t转换成一个格式正确的Tensor。考虑到输入里可能有多个batch,我们先获取batch size n,再根据它来生成t_tensor。
def sample_backward_step(self, x_t, t, net, simple_var=True):
n = x_t.shape[0]
t_tensor = torch.tensor([t] * n,
dtype=torch.long).to(x_t.device).unsqueeze(1)
eps = net(x_t, t_tensor)
之后,我们来处理反向过程公式中的方差项。根据伪代码,我们仅在t非零的时候算方差项。方差项用到的方差有两种取值,效果差不多,我们用simple_var来控制选哪种取值方式。获取方差后,我们再随机采样一个噪声,根据公式,得到方差项。
if t == 0:
noise = 0
else:
if simple_var:
var = self.betas[t]
else:
var = (1 - self.alpha_bars[t - 1]) / (
1 - self.alpha_bars[t]) * self.betas[t]
noise = torch.randn_like(x_t)
noise *= torch.sqrt(var)
最后,我们把eps和方差项套入公式,得到这一步更新过后的图像x_t。
mean = (x_t -
(1 - self.alphas[t]) / torch.sqrt(1 - self.alpha_bars[t]) *
eps) / torch.sqrt(self.alphas[t])
x_t = mean + noise
return x_t
稍后完成了训练后,我们再来看反向过程的输出结果。
训练算法
接下来,我们先跳过神经网络的实现,直接完成论文里的训练算法。
再回顾一遍伪代码。首先,我们要随机选取训练图片�0x0,随机生成当前要训练的时刻�t,以及随机生成一个生成��xt的高斯噪声。之后,我们把��xt和�t输入进神经网络,尝试预测噪声。最后,我们以预测噪声和实际噪声的均方误差为损失函数做梯度下降。
为此,我们可以用下面的代码实现训练。
import torch
import torch.nn as nn
from dldemos.ddpm.dataset import get_dataloader, get_img_shape
from dldemos.ddpm.ddpm import DDPM
import cv2
import numpy as np
import einops
batch_size = 512
n_epochs = 100
def train(ddpm: DDPM, net, device, ckpt_path):
# n_steps 就是公式里的 T
# net 是某个继承自 torch.nn.Module 的神经网络
n_steps = ddpm.n_steps
dataloader = get_dataloader(batch_size)
net = net.to(device)
loss_fn = nn.MSELoss()
optimizer = torch.optim.Adam(net.parameters(), 1e-3)
for e in range(n_epochs):
for x, _ in dataloader:
current_batch_size = x.shape[0]
x = x.to(device)
t = torch.randint(0, n_steps, (current_batch_size, )).to(device)
eps = torch.randn_like(x).to(device)
x_t = ddpm.sample_forward(x, t, eps)
eps_theta = net(x_t, t.reshape(current_batch_size, 1))
loss = loss_fn(eps_theta, eps)
optimizer.zero_grad()
loss.backward()
optimizer.step()
torch.save(net.state_dict(), ckpt_path)
代码的主要逻辑都在循环里。首先是完成训练数据�0x0、�t、噪声的采样。采样�0x0的工作可以交给PyTorch的DataLoader完成,每轮遍历得到的x就是训练数据。�t的采样可以用torch.randint函数随机从[0, n_steps - 1]取数。采样高斯噪声可以直接用torch.randn_like(x)生成一个和训练图片x形状一样的符合标准正态分布的图像。
for x, _ in dataloader:
current_batch_size = x.shape[0]
x = x.to(device)
t = torch.randint(0, n_steps, (current_batch_size, )).to(device)
eps = torch.randn_like(x).to(device)
之后计算��xt并将其和�t输入进神经网络net。计算��xt的任务会由DDPM类的sample_forward方法完成,我们在上文已经实现了它。
x_t = ddpm.sample_forward(x, t, eps) eps_theta = net(x_t, t.reshape(current_batch_size, 1))
得到了预测的噪声eps_theta,我们调用PyTorch的API,算均方误差并调用优化器即可。
loss_fn = nn.MSELoss()
optimizer = torch.optim.Adam(net.parameters(), 1e-3)
...
loss = loss_fn(eps_theta, eps)
optimizer.zero_grad()
loss.backward()
optimizer.step()
去噪神经网络
在DDPM中,理论上我们可以用任意一种神经网络架构。但由于DDPM任务十分接近图像去噪任务,而U-Net又是去噪任务中最常见的网络架构,因此绝大多数DDPM都会使用基于U-Net的神经网络。
我一直想训练一个尽可能简单的模型。经过多次实验,我发现DDPM的神经网络很难训练。哪怕是对于比较简单的MNIST数据集,结构差一点的网络(比如纯ResNet)都不太行,只有带了残差块和时序编码的U-Net才能较好地完成去噪。注意力模块倒是可以不用加上。
由于神经网络结构并不是DDPM学习的重点,我这里就不对U-Net的写法做解说,而是直接贴上代码了。代码中大部分内容都和普通的U-Net无异。唯一要注意的地方就是时序编码。去噪网络的输入除了图像外,还有一个时间戳t。我们要考虑怎么把t的信息和输入图像信息融合起来。大部分人的做法是对t进行Transformer中的位置编码,把该编码加到图像的每一处上。
import torch
import torch.nn as nn
import torch.nn.functional as F
from dldemos.ddpm.dataset import get_img_shape
class PositionalEncoding(nn.Module):
def __init__(self, max_seq_len: int, d_model: int):
super().__init__()
# Assume d_model is an even number for convenience
assert d_model % 2 == 0
pe = torch.zeros(max_seq_len, d_model)
i_seq = torch.linspace(0, max_seq_len - 1, max_seq_len)
j_seq = torch.linspace(0, d_model - 2, d_model // 2)
pos, two_i = torch.meshgrid(i_seq, j_seq)
pe_2i = torch.sin(pos / 10000**(two_i / d_model))
pe_2i_1 = torch.cos(pos / 10000**(two_i / d_model))
pe = torch.stack((pe_2i, pe_2i_1), 2).reshape(max_seq_len, d_model)
self.embedding = nn.Embedding(max_seq_len, d_model)
self.embedding.weight.data = pe
self.embedding.requires_grad_(False)
def forward(self, t):
return self.embedding(t)
class ResidualBlock(nn.Module):
def __init__(self, in_c: int, out_c: int):
super().__init__()
self.conv1 = nn.Conv2d(in_c, out_c, 3, 1, 1)
self.bn1 = nn.BatchNorm2d(out_c)
self.actvation1 = nn.ReLU()
self.conv2 = nn.Conv2d(out_c, out_c, 3, 1, 1)
self.bn2 = nn.BatchNorm2d(out_c)
self.actvation2 = nn.ReLU()
if in_c != out_c:
self.shortcut = nn.Sequential(nn.Conv2d(in_c, out_c, 1),
nn.BatchNorm2d(out_c))
else:
self.shortcut = nn.Identity()
def forward(self, input):
x = self.conv1(input)
x = self.bn1(x)
x = self.actvation1(x)
x = self.conv2(x)
x = self.bn2(x)
x += self.shortcut(input)
x = self.actvation2(x)
return x
class ConvNet(nn.Module):
def __init__(self,
n_steps,
intermediate_channels=[10, 20, 40],
pe_dim=10,
insert_t_to_all_layers=False):
super().__init__()
C, H, W = get_img_shape() # 1, 28, 28
self.pe = PositionalEncoding(n_steps, pe_dim)
self.pe_linears = nn.ModuleList()
self.all_t = insert_t_to_all_layers
if not insert_t_to_all_layers:
self.pe_linears.append(nn.Linear(pe_dim, C))
self.residual_blocks = nn.ModuleList()
prev_channel = C
for channel in intermediate_channels:
self.residual_blocks.append(ResidualBlock(prev_channel, channel))
if insert_t_to_all_layers:
self.pe_linears.append(nn.Linear(pe_dim, prev_channel))
else:
self.pe_linears.append(None)
prev_channel = channel
self.output_layer = nn.Conv2d(prev_channel, C, 3, 1, 1)
def forward(self, x, t):
n = t.shape[0]
t = self.pe(t)
for m_x, m_t in zip(self.residual_blocks, self.pe_linears):
if m_t is not None:
pe = m_t(t).reshape(n, -1, 1, 1)
x = x + pe
x = m_x(x)
x = self.output_layer(x)
return x
class UnetBlock(nn.Module):
def __init__(self, shape, in_c, out_c, residual=False):
super().__init__()
self.ln = nn.LayerNorm(shape)
self.conv1 = nn.Conv2d(in_c, out_c, 3, 1, 1)
self.conv2 = nn.Conv2d(out_c, out_c, 3, 1, 1)
self.activation = nn.ReLU()
self.residual = residual
if residual:
if in_c == out_c:
self.residual_conv = nn.Identity()
else:
self.residual_conv = nn.Conv2d(in_c, out_c, 1)
def forward(self, x):
out = self.ln(x)
out = self.conv1(out)
out = self.activation(out)
out = self.conv2(out)
if self.residual:
out += self.residual_conv(x)
out = self.activation(out)
return out
class UNet(nn.Module):
def __init__(self,
n_steps,
channels=[10, 20, 40, 80],
pe_dim=10,
residual=False) -> None:
super().__init__()
C, H, W = get_img_shape()
layers = len(channels)
Hs = [H]
Ws = [W]
cH = H
cW = W
for _ in range(layers - 1):
cH //= 2
cW //= 2
Hs.append(cH)
Ws.append(cW)
self.pe = PositionalEncoding(n_steps, pe_dim)
self.encoders = nn.ModuleList()
self.decoders = nn.ModuleList()
self.pe_linears_en = nn.ModuleList()
self.pe_linears_de = nn.ModuleList()
self.downs = nn.ModuleList()
self.ups = nn.ModuleList()
prev_channel = C
for channel, cH, cW in zip(channels[0:-1], Hs[0:-1], Ws[0:-1]):
self.pe_linears_en.append(
nn.Sequential(nn.Linear(pe_dim, prev_channel), nn.ReLU(),
nn.Linear(prev_channel, prev_channel)))
self.encoders.append(
nn.Sequential(
UnetBlock((prev_channel, cH, cW),
prev_channel,
channel,
residual=residual),
UnetBlock((channel, cH, cW),
channel,
channel,
residual=residual)))
self.downs.append(nn.Conv2d(channel, channel, 2, 2))
prev_channel = channel
self.pe_mid = nn.Linear(pe_dim, prev_channel)
channel = channels[-1]
self.mid = nn.Sequential(
UnetBlock((prev_channel, Hs[-1], Ws[-1]),
prev_channel,
channel,
residual=residual),
UnetBlock((channel, Hs[-1], Ws[-1]),
channel,
channel,
residual=residual),
)
prev_channel = channel
for channel, cH, cW in zip(channels[-2::-1], Hs[-2::-1], Ws[-2::-1]):
self.pe_linears_de.append(nn.Linear(pe_dim, prev_channel))
self.ups.append(nn.ConvTranspose2d(prev_channel, channel, 2, 2))
self.decoders.append(
nn.Sequential(
UnetBlock((channel * 2, cH, cW),
channel * 2,
channel,
residual=residual),
UnetBlock((channel, cH, cW),
channel,
channel,
residual=residual)))
prev_channel = channel
self.conv_out = nn.Conv2d(prev_channel, C, 3, 1, 1)
def forward(self, x, t):
n = t.shape[0]
t = self.pe(t)
encoder_outs = []
for pe_linear, encoder, down in zip(self.pe_linears_en, self.encoders,
self.downs):
pe = pe_linear(t).reshape(n, -1, 1, 1)
x = encoder(x + pe)
encoder_outs.append(x)
x = down(x)
pe = self.pe_mid(t).reshape(n, -1, 1, 1)
x = self.mid(x + pe)
for pe_linear, decoder, up, encoder_out in zip(self.pe_linears_de,
self.decoders, self.ups,
encoder_outs[::-1]):
pe = pe_linear(t).reshape(n, -1, 1, 1)
x = up(x)
pad_x = encoder_out.shape[2] - x.shape[2]
pad_y = encoder_out.shape[3] - x.shape[3]
x = F.pad(x, (pad_x // 2, pad_x - pad_x // 2, pad_y // 2,
pad_y - pad_y // 2))
x = torch.cat((encoder_out, x), dim=1)
x = decoder(x + pe)
x = self.conv_out(x)
return x
convnet_small_cfg = {
'type': 'ConvNet',
'intermediate_channels': [10, 20],
'pe_dim': 128
}
convnet_medium_cfg = {
'type': 'ConvNet',
'intermediate_channels': [10, 10, 20, 20, 40, 40, 80, 80],
'pe_dim': 256,
'insert_t_to_all_layers': True
}
convnet_big_cfg = {
'type': 'ConvNet',
'intermediate_channels': [20, 20, 40, 40, 80, 80, 160, 160],
'pe_dim': 256,
'insert_t_to_all_layers': True
}
unet_1_cfg = {'type': 'UNet', 'channels': [10, 20, 40, 80], 'pe_dim': 128}
unet_res_cfg = {
'type': 'UNet',
'channels': [10, 20, 40, 80],
'pe_dim': 128,
'residual': True
}
def build_network(config: dict, n_steps):
network_type = config.pop('type')
if network_type == 'ConvNet':
network_cls = ConvNet
elif network_type == 'UNet':
network_cls = UNet
network = network_cls(n_steps, **config)
return network
实验结果与采样
把之前的所有代码综合一下,我们以带残差块的U-Net为去噪网络,执行训练。
if __name__ == '__main__':
n_steps = 1000
config_id = 4
device = 'cuda'
model_path = 'dldemos/ddpm/model_unet_res.pth'
config = unet_res_cfg
net = build_network(config, n_steps)
ddpm = DDPM(device, n_steps)
train(ddpm, net, device=device, ckpt_path=model_path)
按照默认训练配置,在3090上花5分钟不到,训练30~40个epoch即可让网络基本收敛。最终收敛时loss在0.023~0.024左右。
batch size: 512 epoch 0 loss: 0.23103461712201437 elapsed 7.01s epoch 1 loss: 0.0627968365987142 elapsed 13.66s epoch 2 loss: 0.04828845852613449 elapsed 20.25s epoch 3 loss: 0.04148937337398529 elapsed 26.80s epoch 4 loss: 0.03801360730528831 elapsed 33.37s epoch 5 loss: 0.03604260584712028 elapsed 39.96s epoch 6 loss: 0.03357676289876302 elapsed 46.57s epoch 7 loss: 0.0335664684087038 elapsed 53.15s ... epoch 30 loss: 0.026149748386939366 elapsed 204.64s epoch 31 loss: 0.025854381563266117 elapsed 211.24s epoch 32 loss: 0.02589433005253474 elapsed 217.84s epoch 33 loss: 0.026276464049021404 elapsed 224.41s ... epoch 96 loss: 0.023299352884292603 elapsed 640.25s epoch 97 loss: 0.023460942271351815 elapsed 646.90s epoch 98 loss: 0.023584651704629263 elapsed 653.54s epoch 99 loss: 0.02364126600921154 elapsed 660.22s
训练这个网络时,并没有特别好的测试指标,我们只能通过观察采样图像来评价网络的表现。我们可以用下面的代码调用DDPM的反向传播方法,生成多幅图像并保存下来。
def sample_imgs(ddpm,
net,
output_path,
n_sample=81,
device='cuda',
simple_var=True):
net = net.to(device)
net = net.eval()
with torch.no_grad():
shape = (n_sample, *get_img_shape()) # 1, 3, 28, 28
imgs = ddpm.sample_backward(shape,
net,
device=device,
simple_var=simple_var).detach().cpu()
imgs = (imgs + 1) / 2 * 255
imgs = imgs.clamp(0, 255)
imgs = einops.rearrange(imgs,
'(b1 b2) c h w -> (b1 h) (b2 w) c',
b1=int(n_sample**0.5))
imgs = imgs.numpy().astype(np.uint8)
cv2.imwrite(output_path, imgs)
一切顺利的话,我们可以得到一些不错的生成结果。下图是我得到的一些生成图片:

大部分生成的图片都对应一个阿拉伯数字,它们和训练集MNIST里的图片非常接近。这算是一个不错的生成结果。
如果神经网络的拟合能力较弱,生成结果就会差很多。下图是我训练一个简单的ResNet后得到的采样结果:

可以看出,每幅图片都很乱,基本对应不上一个数字。这就是一个较差的训练结果。
如果网络再差一点,可能会生成纯黑或者纯白的图片。这是因为网络的预测结果不准,在反向过程中,图像的均值不断偏移,偏移到远大于1或者远小于-1的值了。
总结一下,在复现DDPM时,最主要是要学习DDPM论文的两个算法,即训练算法和采样算法。两个算法很简单,可以轻松地把它们